In this study we show how to use Mighty Inference Server to quickly get dense vectors for the entire eCFR (electronic Code of Federal Regulations) on a very small budget. The setup time is less than 5 minutes, and the processing time is 22 minutes with cloud costs of about $3.00. We chose the eCFR as it represents a true real-world dataset that is used by thousands of organizations and millions of people every day.
The eCFR is structured as a hierarchy, and in order to process the text in a way that aligns with how people use the eCFR, we work at the paragraph level, and produce vectors for each paragraph. Experts frequently use citation numbers - for example, the section 42 CFR § 438.100 are the rules for Medicaid Enrollee rights. But if you don't know how to work in this hierarchy, it is difficult to find information. Also, if you don't know the specific keyword "Enrollee", you will spend a long time trying to find what you need. Contemporary search now uses dense vectors that embed language meaning, so recall is much more robust. We can use this technique (and a vector search engine) to search for similar terms and find what we need, even if we don't know the exact keywords.
High throughput on a shoestring budget
Converting text to vectors is usually slow and expensive. As of March 2022, the eCFR has 275,848 sections. Each section contains one to many paragraphs with up to six levels. All together, there are 2 million paragraphs which total 522MB of text. Using a paid API to process these paragraphs to vectors would take hours and cost thousands of dollars. We're going to do it in under a half-hour for less than a cup of coffee.
The hot topic in AI inference is typically latency - how quickly a model will process input to get the output. Latency is important for production querying, and being able to process queries quickly so the service isn't slow for customers. But when preparing and processing content at scale for large collections - throughput (or bandwidth) is equally important.
Let's visualize: If you need to fill a swimming pool, and you have a small hose with a lot of pressure - the water will flow quickly but filling the pool will still take a long time. However, if you have 100 hoses all with the same amount of pressure, the pool will fill even quicker. Adding more hoses increases the throughput even more. Since we want to be able to process as much text as possible in a short amount of time, we're going to do this by having lots of connections between the client and server. Many inference solutions focus on latency alone, but processing content in bulk needs to be economical.
Infrastructure profile
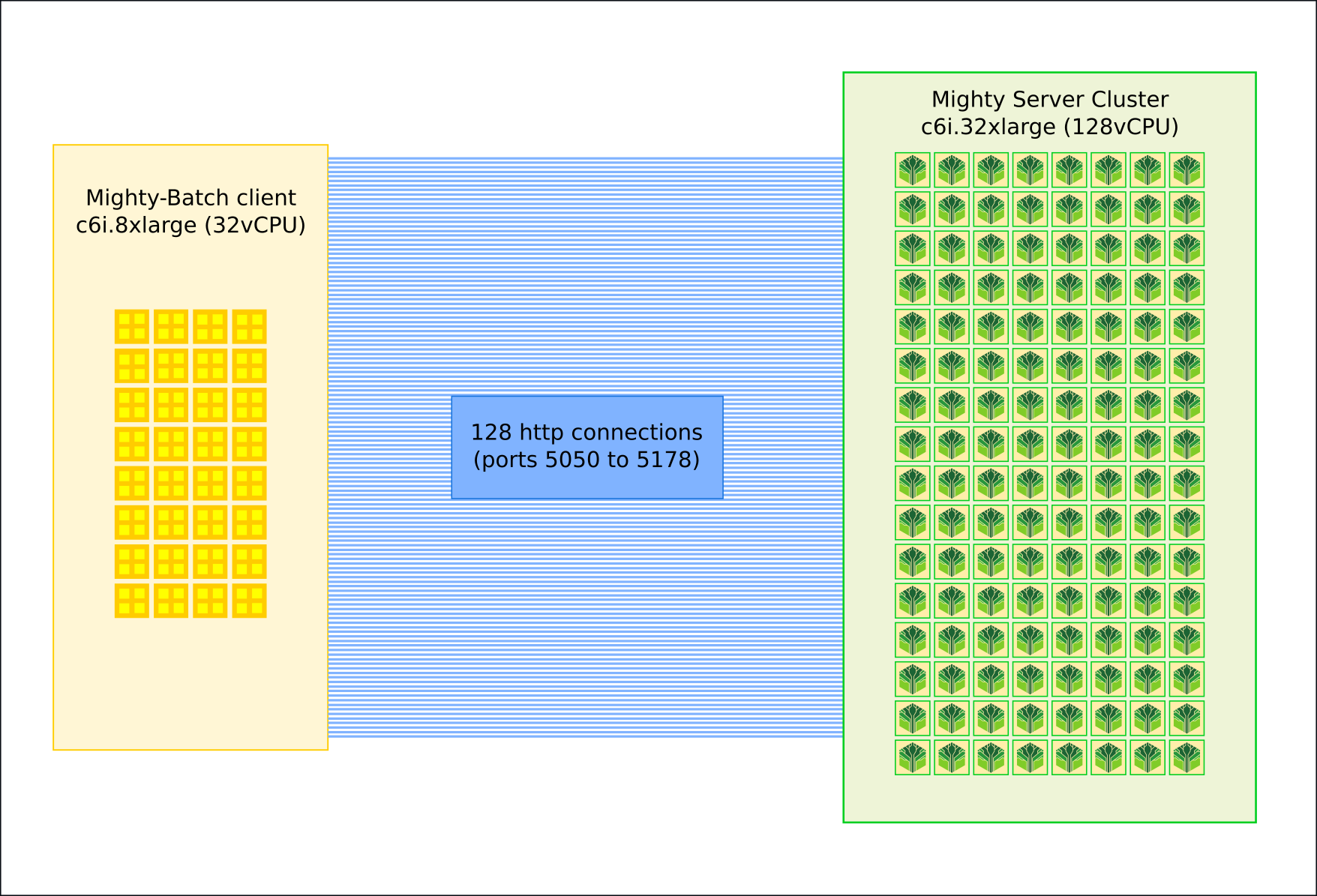
Enter Mighty Inference Server. With Mighty we can scale the throughput to process millions or billions of new documents per day with a reasonable and predictable cost and time. We will use Mighty running in parallel on a cloud instance with 128 CPUs (specifically AWS c6i.32xlarge). We start a Mighty server on each CPU thread - which means we will have 128 Mighty servers running on the same machine simultaneously. Since Mighty is heavily optimized and is only 40MB in size, and the model is only 90MB, we use very little RAM. Our compute and memory use will remain stable, without garbage collection pauses or other issues. We can use this setup to linearly scale to any size of content we need, in any timeframe we need, by adding more CPUs or more servers.
In order to send the data to be processed, we also need an efficient client that can make multiple connections. I created https://github.com/maxdotio/mighty-batch to do just that. Mighty-batch is a concurrent program that will make multiple connections to a mighty-cluster, and send lots of documents in parallel for processing. For this case it will run on a 32 thread instance (specifically AWS c6i.8xlarge). Since the client will spend some time waiting for a document to be processed, one client doesn't need an entire thread. So we use all 32 threads with 4 asynchronous workers per thread, to get 128 total workers in synergy with the 128 core mighty server. Each worker will process some of the content, and all of them collaborating together will churn through everything very quickly. This is a shining example of using parallelism to maximize throughput, and only takes several minutes to setup.
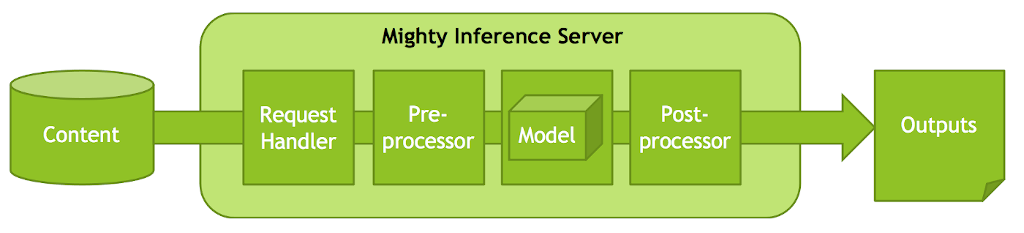
How is this possible? Well, if you zoom in to a single mighty server core, you'd see a complete robust application. Each Mighty server has REST web server, preprocessor, inference runtime, and postprocessor, to handle the entire pipeline. It takes in text, and returns vectors and inference metadata. This means we can just send in text from the light mighty-batch client, and Mighty does all the work.
Each Mighty server in the cluster gets its own unique http port (in this case, between 5050 and 5178 for all 128 servers), and each client worker will connect to and communicate with one specific server. This really easy to scale, without bottlenecks such as reverse proxies or orchestration, and makes everything simple to understand. Simply get out your calculator, and use this reference for how many bytes per second you need to process - and you've got a predictable infrastructure cost plan.
The Sentence-Transformers model
For the model itself, we will use sentence-transformers/all-MiniLM-L6-v2 converted to ONNX. Tokenization and Mean-Pooling are performed during pre and post processing, respectively. Also importantly, long text is split up and processed automatically by Mighty. So if you send in a long paragraph that's too big for the model inputs, it will slice it up and provide as many vectors as needed.
You can use other models too! You can clone https://github.com/maxdotio/mighty-convert and specify a Hugging Face sentence-transformers model of your choice.
Running the batch inference
These steps are easy to follow for anyone with some Ubuntu and AWS experience. We will cover how to setup and prepare the client first. This will save some pennies by starting the big inference server only when we're ready
Preparing the content and client:
- Launch the c6i.8xlarge AWS instance, and install git. Give yourself 50GB of EBS disk to have enough room for the vectors.
- Install Node.js v16 (using https://github.com/nvm-sh/nvm and then nvm install v16) - required for Mighty-Batch.
- Clone mighty-batch: git clone https://github.com/maxdotio/mighty-batch
- Install the Java runtime (sudo apt install default-jre) - required to convert ECFR to JSON
- Download and convert the eCFR content: git clone https://github.com/maxdotio/ecfr-prepare and run ./acquire.sh
- Move the converted parts folder into the mighty-batch folder
When creating and starting the Mighty cluster, we just need to do the following:
- Launch the c6i.32xlarge AWS instance, and configure the security group to open the ports from 5050 to 5178 for the client IP address.
- Connect to the instance and download and install Mighty, which takes less than a minute: https://max.io/download.html#linux
- Start the server with the command ./mighty-cluster --sentence-transformers --host 0.0.0.0
- Run top to monitor the CPU use, and keep the session open
When the cluster is running, we can start the content processing:
- Connect to the client machine and cd mighty-batch
- Start the mighty-batch client with 32 threads, 4 workers per thread, and the host IP of the Mighty cluster instance: node multi.js -t 32 -w 4 -m 1 -x 50 -h [IP OF MIGHTY c6i.32xlarge INSTANCE]
- Open another ssh connection to the mighty-batch client server and run top to monitor the node.js processes.
You'll see the status bar move along on the client until it's done:
Inferring [====================================] 100% remaining:0.0s elapsed:1346.6 (275848/275848)
The entire inference takes 22 minutes once you start, and produces 19GB of vectors in the mighty-batch/vectors folder. Remember to stop the servers after you are done to turn of the AWS billing! Here's a screenshot of the batch inference in action:
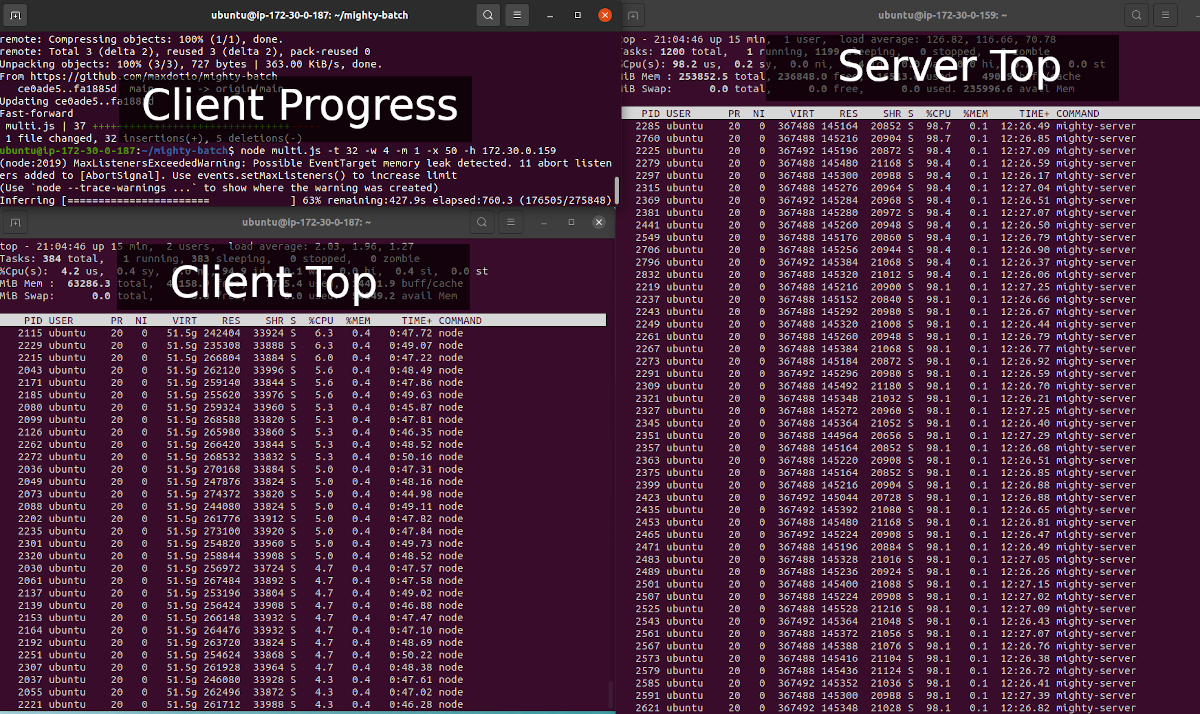
Interpreting the server and client load
Notice in the "Server Top" panel on the right - lots of `mighty-server` processes all running at full capacity with greater than 98% CPU - which is exactly what we want. We're running so many mighty-server processes (128), that they don't even fit on the screen! And, we are using all the available compute on the machine and not being wasteful.
Also importantly, the Memory use is very low per mighty-server. Each vCPU has 2GB of RAM available, and Mighty uses 10% of that - about 200MB. This shows that memory stability and portability are perfect.
For the Client Top panel, we can see much lower CPU per client thread (we have 32 of these each with 4 workers). This means we can probably reduce the number of threads, and increase the workers, so we can use a smaller instance - perhaps with only 16 CPUs (or maybe only 8!).
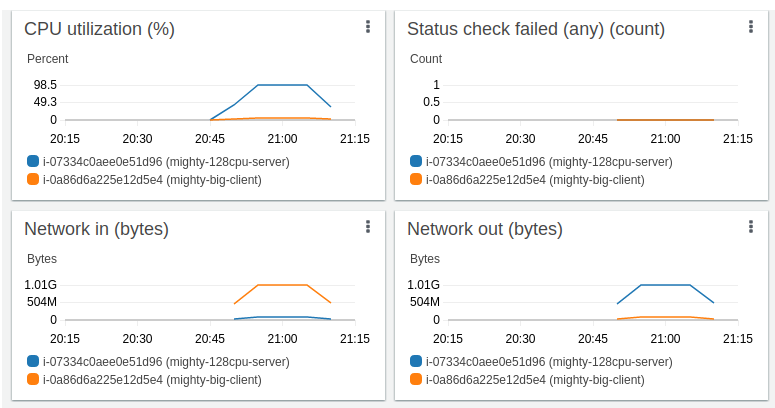
Here is the AWS Dashboard for the entire run, which shows the full duration CPU and Network I/O for each instance:
Results
Cost breakdown
If you are careful to only start the instances when you are using them, and turn them off afterwards, you'll pay about $3.11, including setup time! The volume for the client will contain the vectors that can be used further.
$5.44/h * 0.42(25 mins) = $2.28 ( mighty-128cpu-server -- c6i.32xlarge )
$1.66 * 0.5(30 mins) = $0.83 ( mighty-32cpu-client -- c6i.8xlarge )
Total cost: $3.11
Costs less than a cup of coffee, runs during a short lunch break, and produces 19GB of vectors.
See the full Documentation or Purchase a license. Thanks for reading, and see you next time!
Discuss this post on: